Introducing OrangeDB: A Distributed Key-Doc Database
A couple of months ago, I started building a small LSM tree-based storage engine, which I call Parrot.
If you’re unfamiliar with LSM trees—unlike B-trees, which require frequent reorganizations—LSM (Log-Structured Merge) trees write data as sequential logs. One of the main problems with B/B+ trees is write amplification. Inserting a single row might trigger multiple rearrangements across various index trees, leading to costly random disk writes, especially in persistent systems.
LSM trees avoid this by leveraging sequential writes, making write operations extremely fast. But there’s a tradeoff—read performance. Since records are spread across multiple levels, a read operation might need to scan through several files until it finds the desired record.
Read more about LSM here.
What Makes Parrot Different?
Parrot isn’t just another LSM tree engine. It includes several optimizations aimed at speeding up I/O and improving concurrency.
-
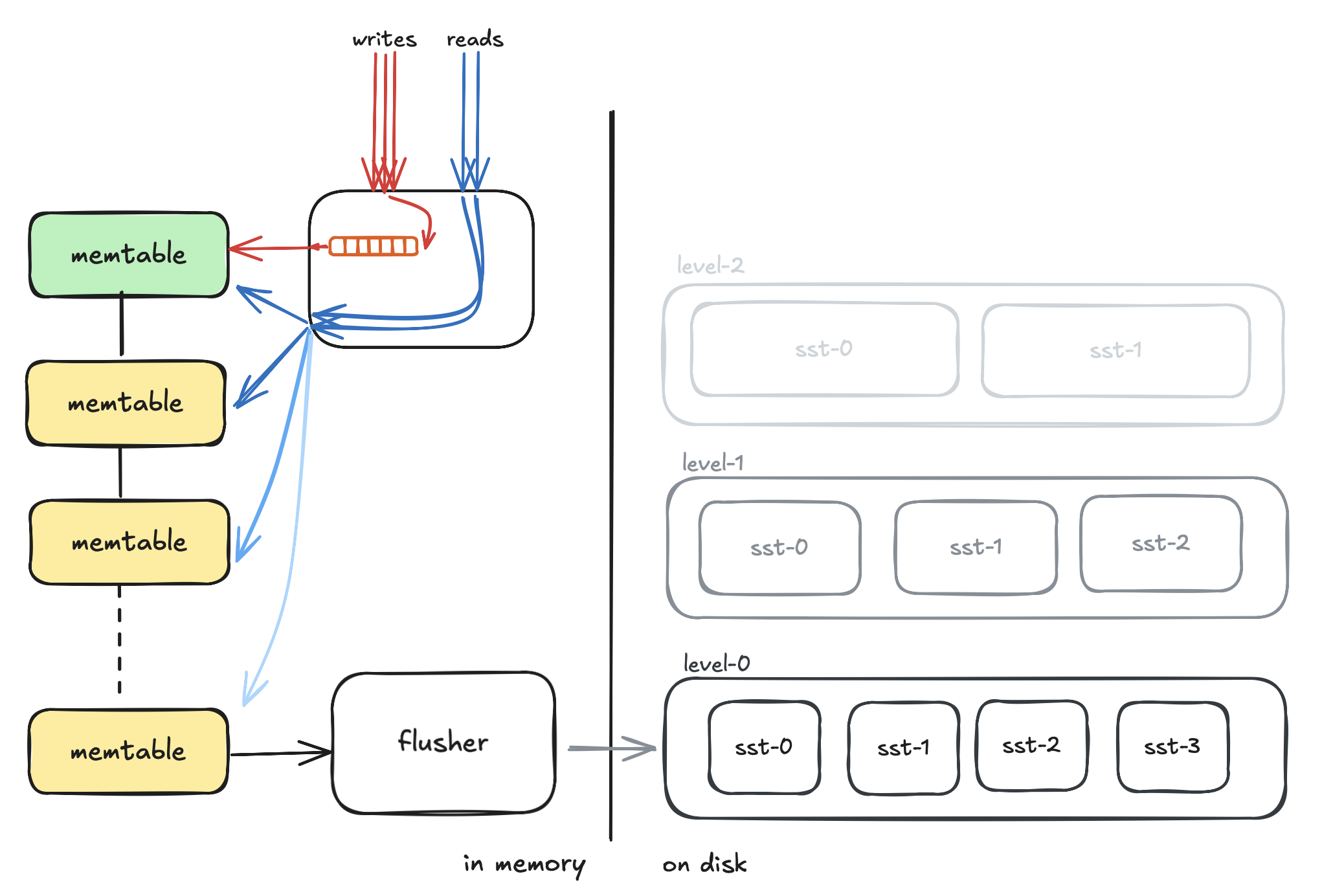
Chain of Memtables
What happens to writes while flushing the memtable? Many systems use a double-buffered approach—write to one while flushing the other. But if the second also fills up before flushing completes, things get messy.
Parrot uses a chain of memtables, where new memtables are continuously added to a queue. The flusher works independently, flushing from the other end of the queue, enabling uninterrupted writes. -
Optimistic Concurrency Control
Parrot minimizes locking, using optimistic strategies for concurrent writes and reads. -
Zero-Copy Reads
Parrot uses shared memory mapping (mmap) to read files. It avoids copying file data to user-space buffers; threads read directly from the kernel page cache, reducing latency and memory usage.
Introducing OrangeDB
Orange is a distributed key-document database built on top of Parrot. It provides:
- SQL-like interface via OQL
- Native JSON-like document encoding
- Rich set of data types
- Sharding and replication out of the box
Sharding, Consistency, and Replication
OrangeDB combines the architectures of MongoDB and Cassandra, striking a balance between high availability and consistency.
An Orange cluster consists of three main components:
-
Router
Uses consistent hashing to route queries to the appropriate shard. It also supports a concept we call “consistent ring within a consistent ring” to map keys precisely to replicas. -
Shard
A group of replicas (or “siblings”) running OrangeDB instances. These replicas use a leaderless model—any replica that receives a write replicates it to others, similar to Cassandra’s gossip-style replication. -
Operator
A custom Kubernetes Operator for deploying and managing OrangeDB clusters.
Read Consistency Levels
OrangeDB supports configurable read strategies:
-
all
Queries all siblings of a shard and requires unanimous agreement on the value.
If any replica is out of sync, the read fails.
This mode provides strong consistency, but may have higher latency. -
quorum
Queries all siblings but only requires a majority to agree on the value.
Offers a balance between consistency and availability.
Can optionally trigger read repair to sync outdated replicas. -
single
Queries only the primary replica responsible for the key.
This is the fastest mode but assumes the primary is alive and up-to-date.
Suitable when you need strong consistency with low latency, but primary node is a single point of failure.
Deployment Options
OrangeDB is available in multiple flavors.
Standalone Mode
Run a single OrangeDB instance with gRPC endpoints. Use the Go client to send OQL or gRPC-based queries.
app % orange server --port 8000
___
/ _ \ _ __ __ _ _ __ __ _ ___
| | | | '__/ _' | '_ \ / _' |/ _ \
| |_| | | | (_| | | | | (_| | __/
\___/|_| \__,_|_| |_|\__, |\___|
|___/
Running project: `orange`
Starting server at 127.0.0.1:8000
You can interact with it using the REPL:
app % orange repl --port 8000 --address localhost
# Welcome to orange
> SELECT * FROM users WHERE _ID = 10
Sharded Cluster on Kubernetes
Step 1: Deploy OrangeDB Operator
kubectl apply -f https://raw.githubusercontent.com/nagarajRPoojari/orangectl/main/dist/install.yaml
Step 2: Define Orange Cluster
# orange.yaml
apiVersion: ctl.orangectl.orange.db/v1alpha1
kind: OrangeCtl
metadata:
name: orangectl-sample
labels:
app.kubernetes.io/name: orangectl
app.kubernetes.io/managed-by: kustomize
spec:
namespace: default
router:
name: router
labels:
app: orange-router
tier: control
image: np137270/gateway:latest
port: 8000
config:
ROUTING_MODE: "hash"
LOG_LEVEL: "info"
shard:
name: shard
labels:
app: orange-shard
tier: data
image: np137270/orange:latest
count: 2 # Number of shards
replicas: 2 # Replicas per shard
port: 52001
config:
STORAGE_PATH: "/app/data"
CACHE_ENABLED: "true"
kubectl apply -f orange.yaml
kubectl port-forward svc/router 8000:8000
Step 3: Try Some Queries
echo "Creating schema..."
curl -X POST http://localhost:8000/ \
-H "Content-Type: application/json" \
-d '{"query": "create document test {\"name\":\"STRING\"}"}'
echo "Inserting documents from ID 1 to 20..."
for i in $(seq 1 20); do
curl -s -X POST http://localhost:8000/ \
-H "Content-Type: application/json" \
-d "{\"query\": \"insert value into test {\\\"_ID\\\": $i, \\\"name\\\": \\\"hello-$i\\\"}\"}"
done
echo "Searching for document with _ID = 13..."
curl -X POST http://localhost:8000/ \
-H "Content-Type: application/json" \
-d '{"query": "select * from test where _ID = 13"}'
What’s Next?
OrangeDB is still evolving. We’re working on:
- Transaction support
- Better indexing strategies
- Integration with stream processing engines
Feedback, contributions, and critiques are welcome.